Overview
Our research interests mainly include computer vision, machine learning, and artificial intelligence. Recently, we are focusing on the visual understanding via deep learning, e.g., person re-identification, crowd counting, video/image detection and segmentation, video captioning, cross-modal Retrieval, pose estimation, fine-grained behavior understanding and its application in civil aviation. We also focus on the practical application of civil aviation video surveillance system, including situation awareness, anomaly detection, model compression and edge computing.
Funding
- Research on video big data analysis of passenger flow in Beijing Tianjin Hebei Airports. Tianjin Natural Science Foundation.
- Research and evaluation on collaborative development of Beijing Tianjin Hebei Airport Group. Key Laboratory of Civil Aviation Administration.
- Research on intelligent recognition technology of operation safety based on video monitoring. Key Laboratory of Civil Aviation Administration.
- Human behavior detection, recognition and visualization analysis based on deep learning in crowded environment. Scientific research projects of Central Universities.
- R&D of AI Large Model-Based Auxiliary Disposal System for Airport Emergency Incidents.Shenzhen Airport Artificial Intelligence Application Scenario Project.
Highlights
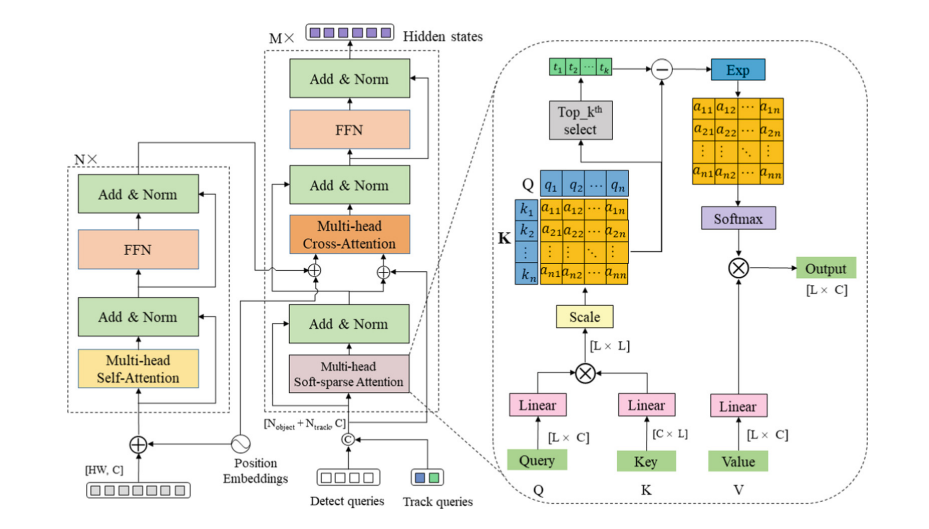
1. Multi-object Tracking
Most existing transformer-based Multi-object tracking (MOT) methods use Convolutional Neural Network (CNN) to extract features and then use a transformer to detect and track objects. However, feature extract networks in existing MOT methods cannot pay more attention to the salient regional features and capture their consecutive contextual information, resulting in the neglect of potential object areas during detection. And self-attention in the transformer generates extensive redundant attention areas, resulting in a weak correlation between detected and tracking objects during the tracking. In this paper, we propose a salient regional feature enhancement module (SFEM) to focus more on salient regional features and enhance the continuity of contextual features, it effectively avoids the neglect of some potential object areas due to occlusion and background interference. We further propose soft-sparse attention (SSA) in the transformer to strengthen the correlation between detected and tracking objects, it establishes an exact association between objects to reduce the object’s ID switch. Experimental results on the datasets of MOT17 and MOT20 show that our model significantly outperforms the state-of-the-art metrics of MOTA, IDF1, and IDSw.
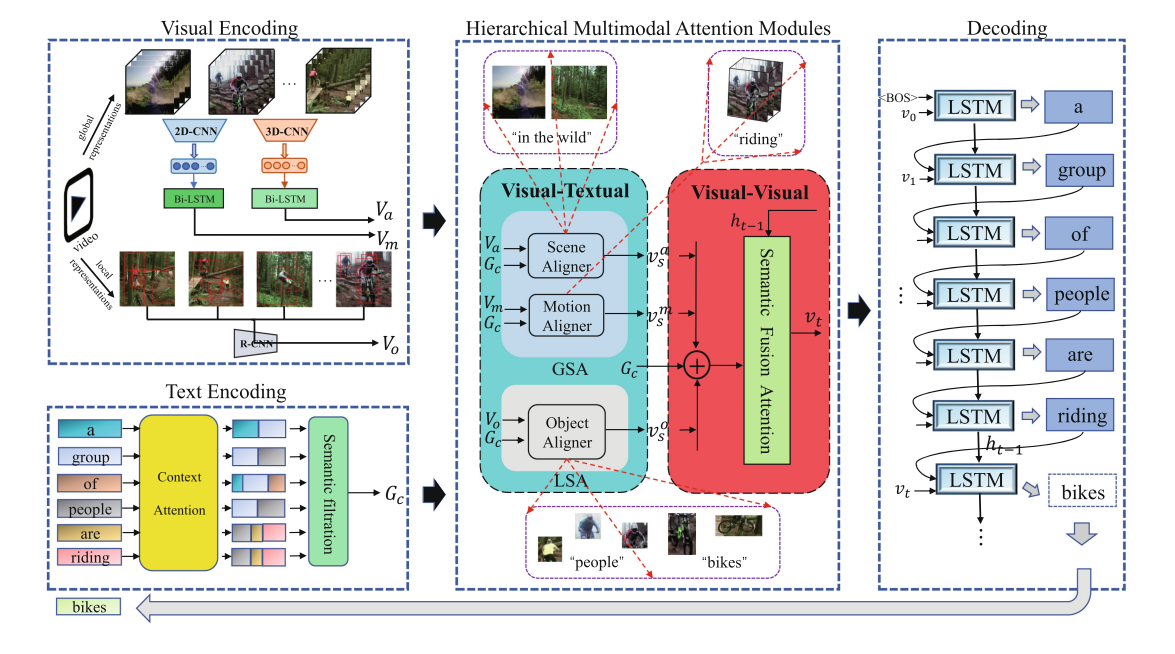
2. Video Caption
Utilizing multiple modal information to understand video semantics is quite natural when humans watch a video and describe its contents with natural language. In this paper, a hierarchical multimodal attention network that promotes the information interactions of visual-textual and visual-visual is proposed for video captioning, which is composed of two attention modules to learn multimodal visual representations in a hierarchical manner. Specifically, visual-textual attention modules are designed for achieving the alignment of the semantic textual guidance and global-local visual representations, thereby leading to a comprehensive understanding of the video-language correspondence. Moreover, the joint modeling of diverse visual representations is learned by the visual-visual attention modules, which can generate compact and powerful video representations to the caption model. Extensive experiments on two public benchmark datasets demonstrate that our approach is pretty competitive with the state-of-the-art methods.
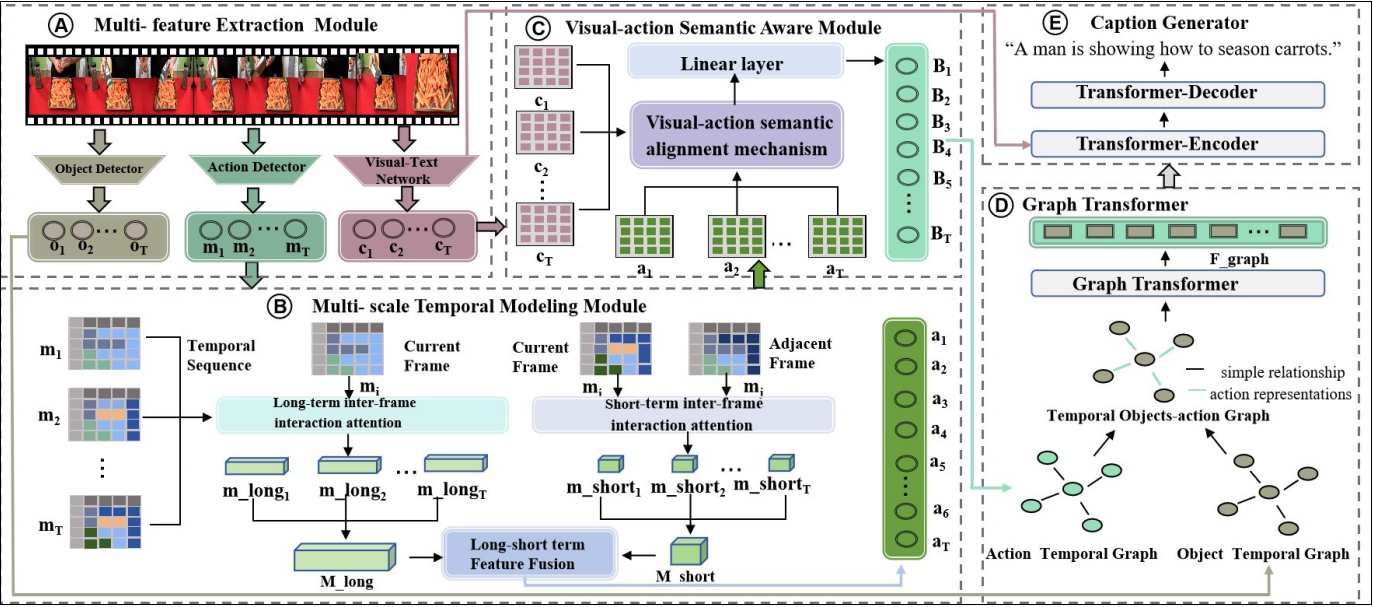
3. Graph-based Behavior Capture Method
In our groundbreaking research, we introduce a novel dynamic action semantic-aware graph transformer that aims to capture more accurate and comprehensive video descriptions. The method addresses key shortcomings in existing video captioning systems by focusing on the dynamic and complex nature of object behaviors. Through the design of a multi-scale temporal modeling module, our approach can effectively learn both long-term and short-term action features. This enables the model to dynamically adjust to the varying importance of actions over time, thus enhancing the richness of behavioral representations. Additionally, a visual-action semantic-aware module is proposed to refine the semantic alignment between visual features and object behaviors, ensuring a deeper understanding of complex actions. Our solution further strengthens the temporal relationship between objects and actions through a graph-based model, resulting in a more robust caption generation. This methodology significantly outperforms traditional models, demonstrating improvements across multiple video captioning benchmarks, including MSVD and MSR-VTT. The comprehensive integration of these advanced modules contributes to achieving state-of-the-art performance and sets a new standard in the field of video captioning.